Let’s break the Hyperflex system !
In the lab there is a 5 node Hyperflex cluster up and running. Everything is healthy and the system is almost for 60% filled, so that is closer to a real test then a lab test. There are several ways to break the cluster and I choose the easiest one. Just power down one random server and see what happens.
If you want to know more about the Auto Healing feature of Hyperflex :
![]()
Summary :
Auto healing kicks in after 2 hours when a node is missing of the Cluster. The cluster is Online, but got a status “Unhealty”. The time of Auto Healing depends of the size and amount of data on your cluster. In my case with a cluster filled of about 50% the repair time is about 3 hours. During these hours the system can still be used without any problems !
Proof that the system is Healthy :
Before I am going to break it, let me show you that the system is a healthy cluster. There are about 200 VM’s running on it with HDParm. See other post.
Although the https://<HX Cluster IP Address>/ui is still under Tech Preview, I am using it to show some things in an easy way.
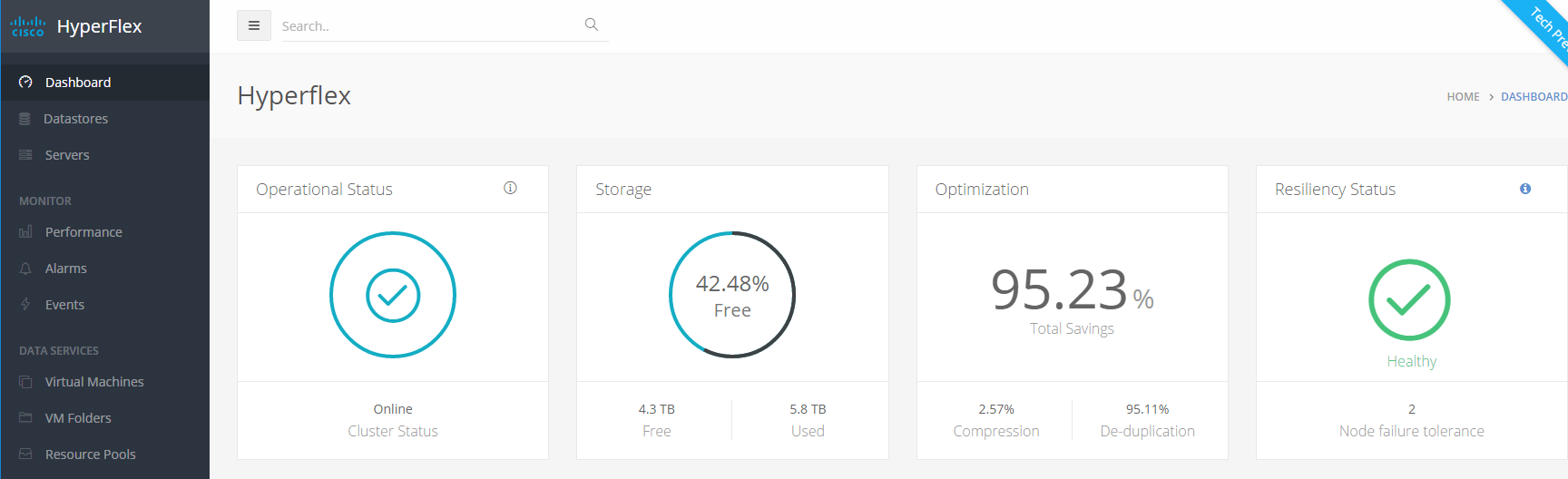
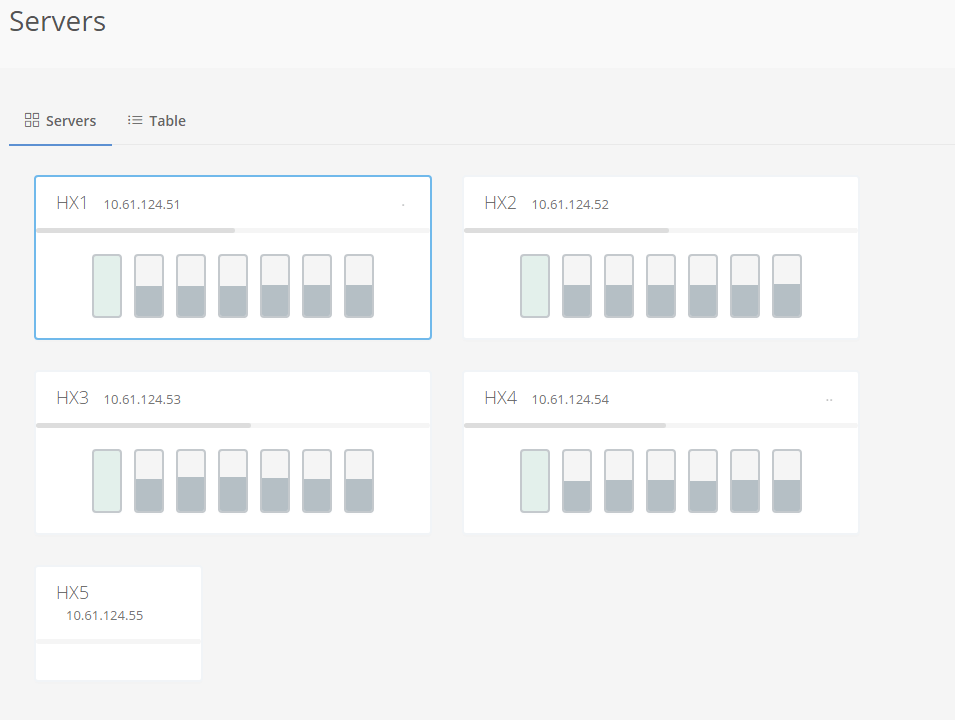
I can see all 5 servers are not having any problems.
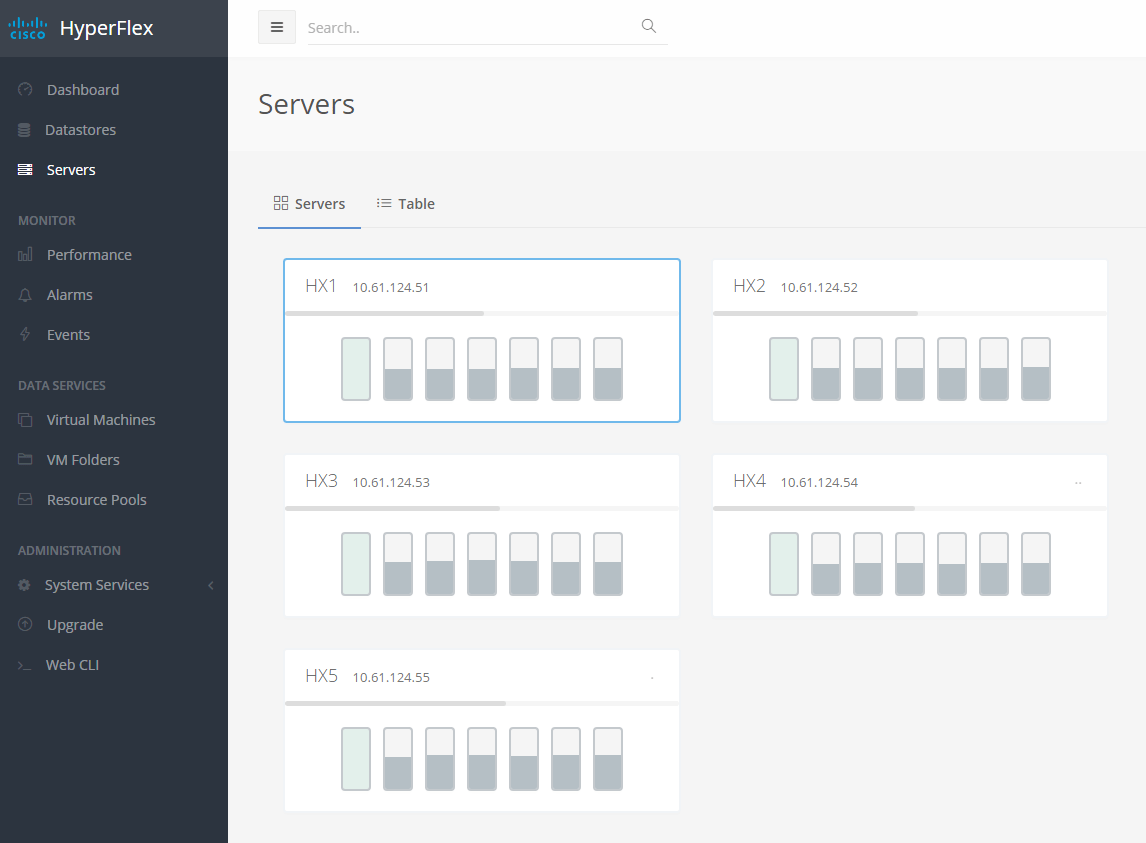
So that you see that the system is working like a normal cluster the next step will be :
And now we break the Hyperflex Cluster :
This can be done is various ways. Nice on, or just power it off. Not gracefully of course otherwise it isn’t a test.
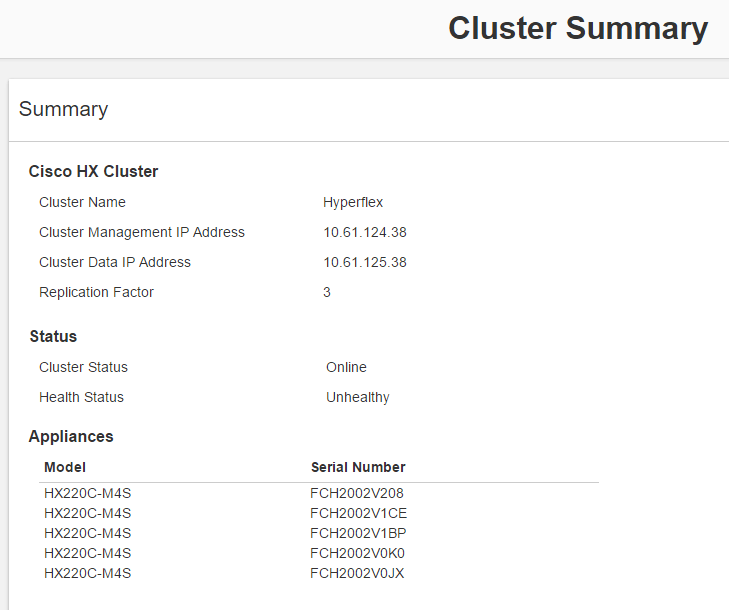
Unhealthy isn’t it ?
Shutting the server down without any grace will make the HX Cluster unhealthy right away.
In vCenter you can also see that the cluster is unhealthy.
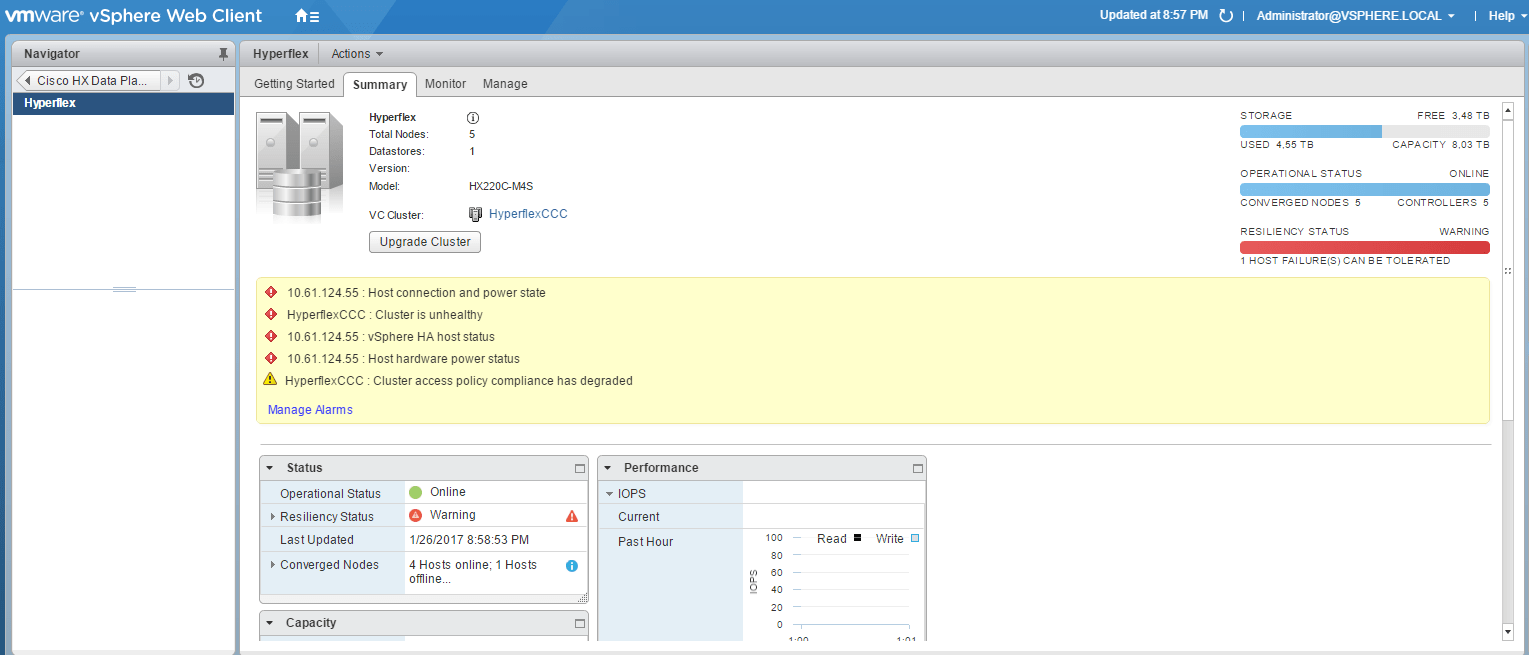
Also on the Dashboard of the UI you see a big red cross which indicates that something isn’t right… right ?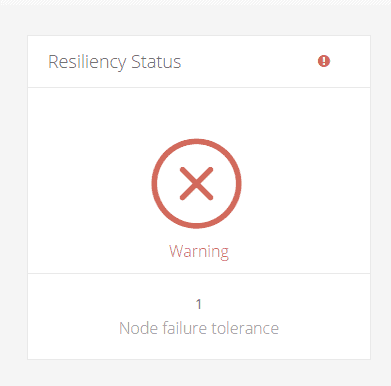
The unhealthy system is also noticed in the Alarms.

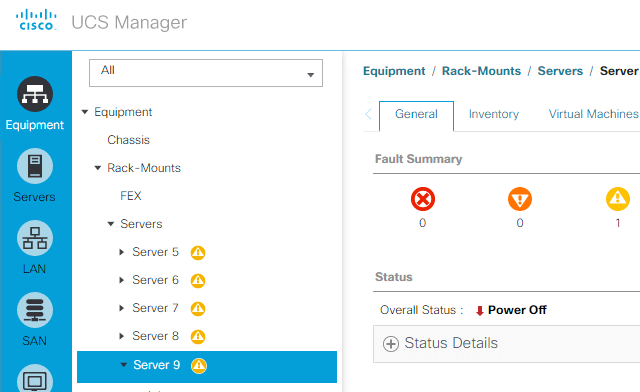
And we can’t get any details of the HX5 server, because it’s powered off.
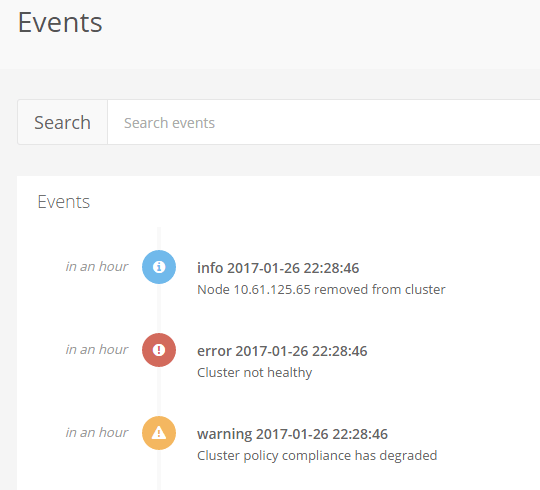
In the events we see the time when the cluster became Unhealthy.
Waiting for 2 hours :
The system is still online, but unhealthy. Autohealing is turned on, but it will kick in after 2 hours of node missing. It could be possible that the node is having maintenance or something. So we will patiently.
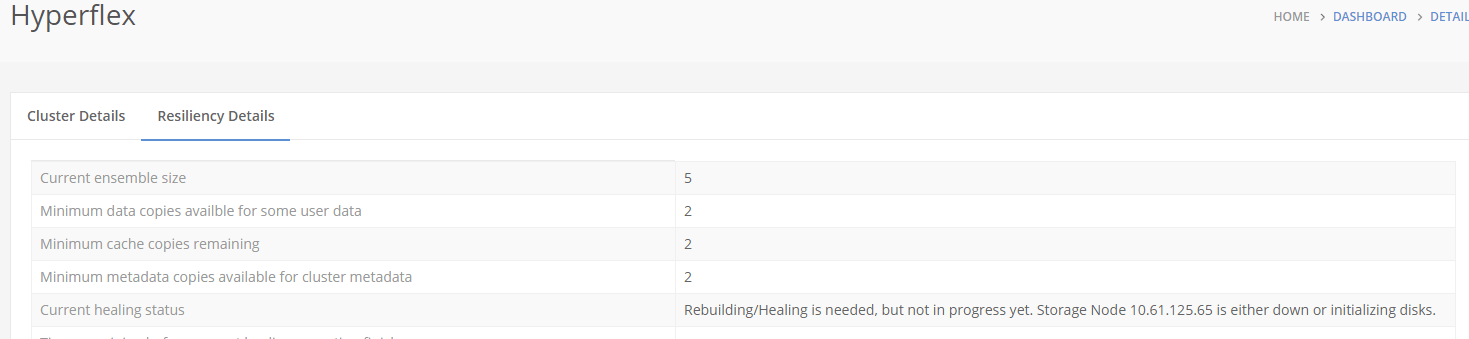
Autohealing is in progress :
Yeah. You will see it’s in progress. The user won’t notice a thing. The system is up and running all the time with all the data on it.

If you click the blue “I” icon you will see : 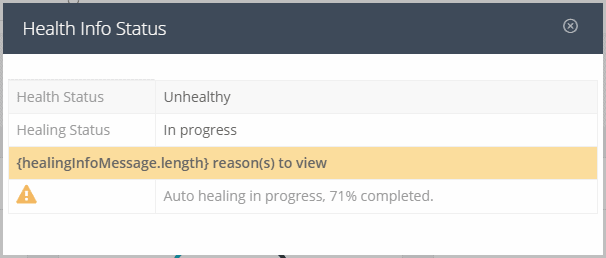
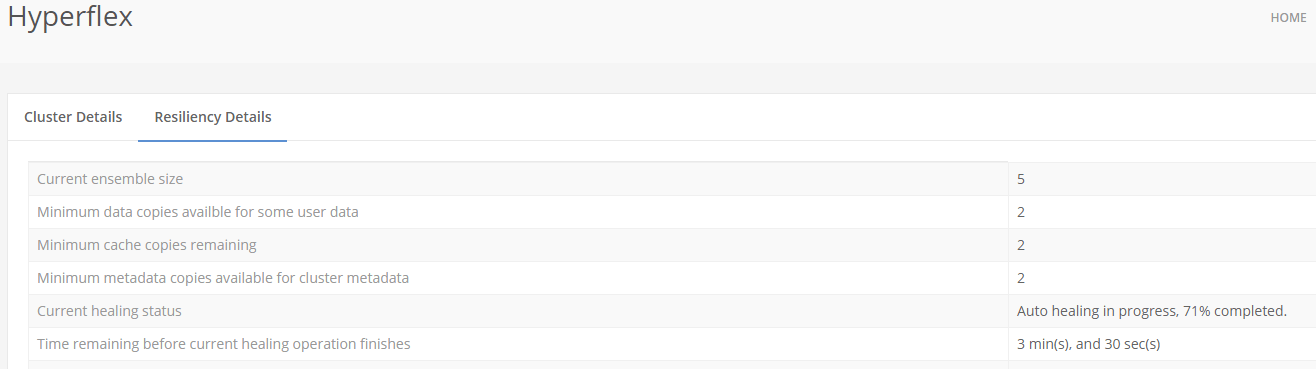
You can see how far the process is. “Time remaining before current healing operations finished” is a wrong sentence ! It’s the time that the system is busy with the Auto Healing Process.
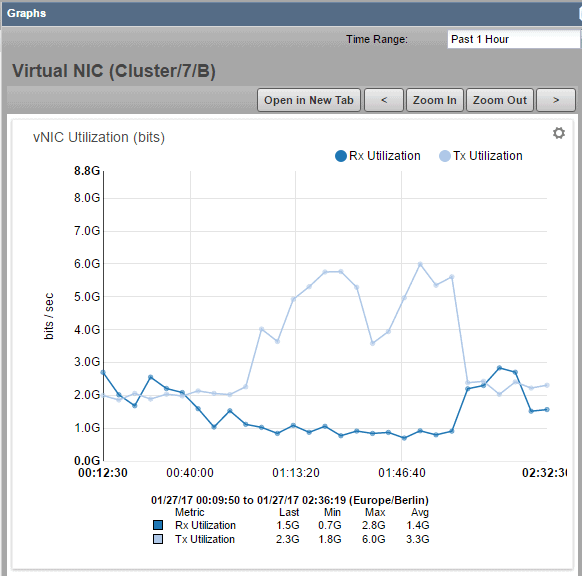
With UCS Performance Manager I can see all the bandwidth that’s being used at the links from and to the HX Systems. When Auto Healing is busy, yeah, there is some more traffic, because we copy all the blocks instead of regenerate it.
Cluster is healthy again :
Just sit back and be patient. The Hyperflex system can take care of itself and after some hours, the system is Healthy again. You will notice in my example that we still have 1 node failure tolerance left !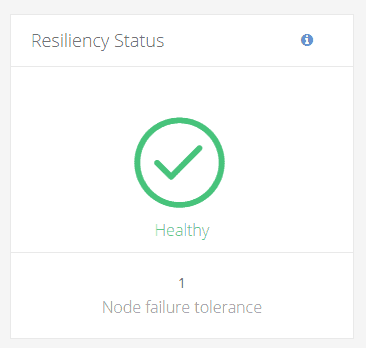
In the Events you will see the time when the system is healthy again. 
Although we do have an Online and Healthy system again, because the system is pretty full, there is no room for Auto Healing when another node is failing again.
The best way to solve this is to expand the cluster again with a node.

Pretty Cool, huh ? If you have any comments or questions, please ask.
I dont know if this still is part of the test. Haha. Would like to ask if all your running VM has migrated from the node that you shutdown to another node? Thanks! 🙂
Hello,
Yes, they were migrated.
Hi Joost,
very well explained !!
But want to know that how much cluster capacity is reduced since one node gets failed?
and can we kick the cluster healing manually instead of waiting for 2 hours. for auto healing?
Yes, the capacity is reduced and with the HX Connect or API you can start self healing.
Hey Joost !
what happens to the cluster capacity when a node is down?
The capacity is less then during normal operation. So you will get up to 70% filled space (with a 4 node cluster) and when 1 node is failing, you almost got now a system that’s filled up to 90%
Hi Joost,
Thanks for the write up and the youtube Videos !
Just have one question in mind, we recently 4 new HFX nodes, we will create a new cluster, however one of the node power state is shown ON, which the rest are shown Off.
How to change the power state to OFF ? as i need to run Platform controller wizard to bring these servers up.
Appreciated your input on this !
You can use the UCS-Manager to power the server off.