Auto Healing !
Hyperflex is cool and I really like this feature. Not only on Powerpoint, but also how it’s working.
You have to ask yourself : How can a system heal itself ? Doesn’t a RAID controller do that for storage ? Why change that into something completely different?
How does it work ?
I assume you know how RAID is working. There are different RAID variants and you can see them in the wiki. Well. It isn’t RAID that is used for the data integrity.
First let’s explain how the data is written to the nodes.
The VM is basically a FILE.VMDK. Let’s split this file into blocks. This time I won’t go in detail. Each block will be placed onto a node. Where the block is written depends on an algorithm.
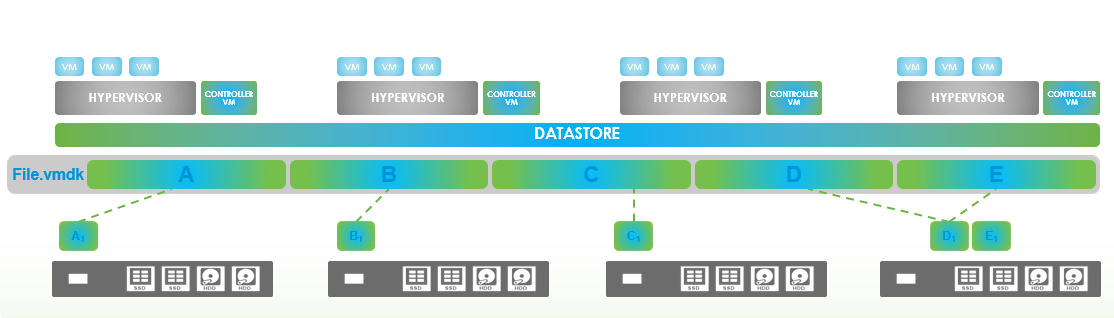
Because the system doesn’t use RAID and we want to have resilience, the Hyperflex system copies every written block to 1 or 2 other nodes. This depends on the Replication Factor (RF). For production it’s better to have a RF of 3, so that every block is written 3 times on the system. The copied blocks won’t be written on a same node where there is already the same block, otherwise you still could have a Single Point Of Failure. As you can see there is no data-locality. That’s okay, because every node is connected to a Fabric Interconnect and this devices does local switching. So even though the data is spread across the cluster, the data is still very fast. Huge bandwidth and no penalties of the RAID.
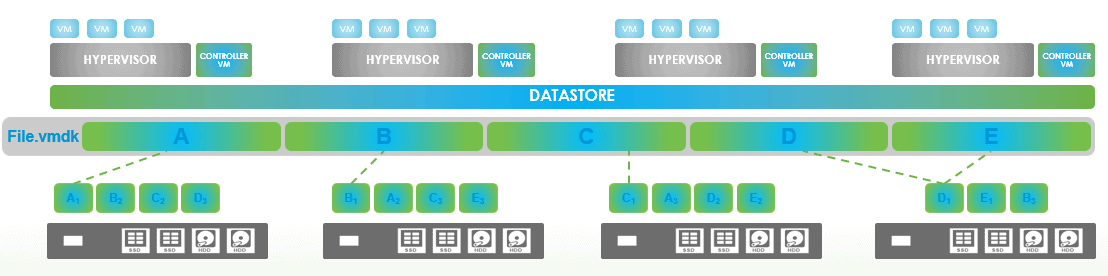
If a node is shutdown or something happens with it, we’re missing some blocks on the system.
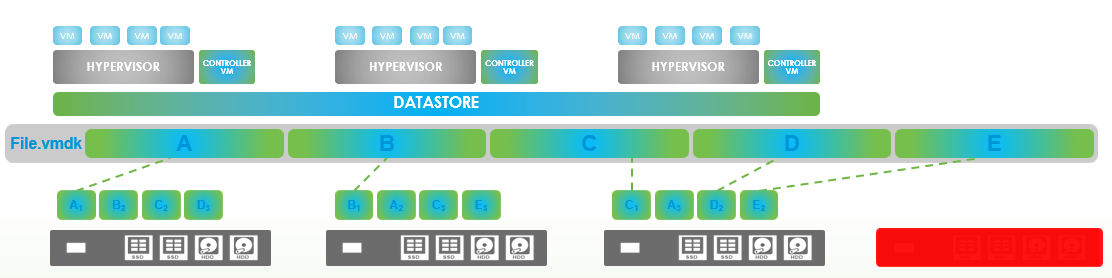
After 2 hours the Auto Healing will kick in and the system will COPY the missing block. Because it’s a COPY and not a rebuild of a RAID set, it’s very fast. The blocks are written with an algorithm that each node only got a maximum of 1 block of the 3 same blocks.
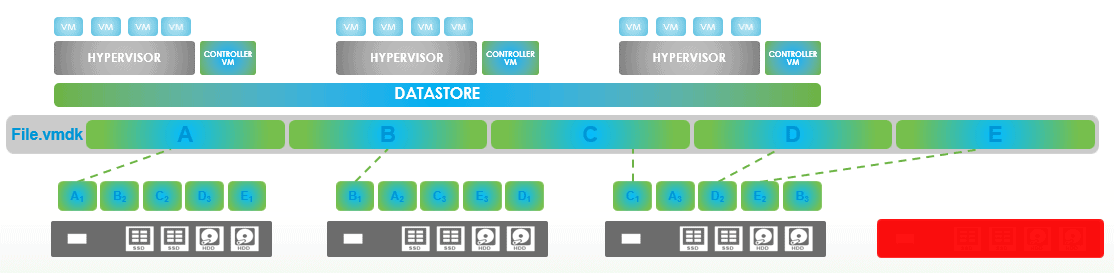
The principle of Auto Healing is easy and fast without any interruption of the business !
So far all the writtens. Do you want prove that it is working ? See my Post : ![]()